สร้างเว็บให้มีประสิทธิภาพ ด้วย 12 บัญญัติจาก Twelve Factor App

การพัฒนาเว็บแอพพลิเคชันนั้นไม่ใช่ของง่าย หากเราวางโครงสร้างระบบไม่ดีพอ การเปลี่ยนแปลงเพียงเล็กน้อยย่อมส่งผลให้เราต้องรับบาปขุดโค้ดเก่ามาแก้ใหม่ เพื่อนๆบางคนที่ชะตากรรมถึงฆาตแล้ว ทดสอบแอพบนเครื่องเราก็ดีอยู่หรอก พอ Deploy ขึ้น Production ความบรรลัยเกิดขึ้นทันที เกลียด!
The Twelve-Factor App เป็นบัญญัติ 12 ประการที่จะช่วยวางโครงสำหรับการสร้าง Software as a Service (Web Application) ที่สาวกผู้ใช้ Ruby on Rails ย่อมรู้จักกันดีมาตั้งแต่ชาติปางก่อน ยิ่งถ้าเพื่อนๆคนไหนใช้ Heroku ด้วยแล้วยิ่งต้องรู้จักเลยหละ ไม่เช่นนั้นจะถือว่าทรยศต่อแพลตฟอร์มเป็นอย่างยิ่ง!
บทความนี้จะเป็นรถไฟตระเวนสวนสัตว์ของ 12factor เราจะได้รู้จักบัญญัติทั้ง 12 ประการที่จะช่วยให้การ build แอพพลิเคชันของเราดีขึ้น แล้วคุณจะรู้ว่า 12factor ไม่ใช่รถไฟธรรมดา แต่เป็นรถไฟเหาะตีลังกาสามตลบที่จะทำให้คุณบรรลุจุดยอดของการส่งมอบ Web App ไปสู่ Production แน่นอน ฟันธง!
รู้จัก The Twelve-Factor App
ยาวไปไม่อ่าน: อ่านเหอะ 4-5 บรรทัดเองนะ เค้าขอร้อง~
Cloud Platform สมัยนี้ขยายตัวเร็วดั่งเชื้อราบนหนังศรีษะ ผุดกันเป็นดอกเห็ดจนยากที่จะหาผู้ใดเป็นเจ้า Platform อย่างแท้จริงได้ ในฐานะผู้บริโภค ศรัทธาต่อผู้ให้บริการก็ส่วนหนึ่ง แต่เราพร้อมจะย้ายค่ายทันทีหาก Platform อื่นถูกกว่าและลื่น~ // DTAC ค่ะ
เมื่ออำนาจเงินตราคือพ่อพระเจ้า เราต้องทำแอพพลิเคชันของเราให้ไม่ขึ้นกับผู้ให้บริการใดๆ เพื่อสะดวกต่อการโอนสัมมโนครัวย้ายไป Platform อื่น เมื่อรักเราคืออดีต แผนการชั่วร้ายจึงเกิดขึ้น!
Adam Wiggins ผู้ร่วมก่อตั้งของ Heroku, บริการกลุ่มเมฆชื่อดังที่แม้แต่เด็กอนุบาลหมีน้อยยังรู้จัก, ได้เผยแพร่กฎเหล็ก 12 ประการจากประสบการณ์ในการพัฒนาแอพพลิเคชันบนแพลตฟอร์มของ Heroku ในชื่อของ Twelve Factor App บัญญัติดังกล่าวจะช่วยให้แอพพลิเคชันของเรา Strong แบบพี่ลูกเกด, บำรุงรักษาง่าย และแน่นอนว่าแอพเราจะไม่ขึ้นกับ Platform ใดๆ
Twelve Factor App เป็นหลักการที่เหมาะกับการพัฒนาแอพพลิเคชันใดๆ โดยเฉพาะอย่างยิ่งแอพพลิเคชันที่มีการให้บริการผ่านอินเตอร์เน็ต (Software as a Service)
สาธยายมาซะขนาดนี้ คงอยากรู้กันแล้วซิว่าบัญญัติทั้ง 12 ประการมีอะไรบ้าง...
บัญญัติข้อที่ 1: Codebase
ยาวไปไม่อ่าน: จัดเก็บแอพพลิเคชันในหนึ่ง Codebase เท่านั้น ส่วนจะ Deploy กี่ครั้ง ถามใจเธอดู~
สมัยนี้คงไม่มีใครเขียนโค้ดเก็บในเครื่องโดยไม่ใช้ Version Control เช่น Git หรือ SVN แล้วใช่ไหมฮะ ถ้าคุณใช้สิ่งเหล่านี้อยู่ ดีใจด้วยคุณบรรลุกฎข้อแรกไปครึ่งทางแล้ว...
กฎเหล็กข้อแรกกล่าวไว้ว่า คุณต้องใช้ Version Control เช่น Git หรือ SVN และที่สำคัญหนึ่ง Codebase ต้องจัดเก็บเพียงหนึ่งแอพพลิเคชันเท่านั้น อารมณ์ประมาณว่าถ้าคุณมีเมียหลวง คุณก็ไม่ควรมีเมียน้อย เพราะมันจะสับรางลำบากยังไงละ!
บัญญัติข้อนี้กล่าวไว้ว่า Codebase เดียวของเรา จะเก็บโค้ดของแอพเดียว ห้ามแชร์ Codebase นี้เพื่อสร้างแอพอื่นด้วย นั่นเพราะ Codebase เสมือนเป็นบ้านหลังนึงของเรา ส่วนแอพพลิเคชันเป็นดั่งภรรยาแสนน่ารักทั้งหลาย ถ้าคุณยังไม่อยากตายไว คุณไม่ควรให้เมียหลวงและเมียน้อยมาสุมหัวอยู่ในบ้านหลังเดียวกัน! บอกเลยนี่ยังไม่รวมเมียเก็บนะ แค่คิดก็ศพไม่สวยละ
แม้ Codebase หนึ่งๆจะใช้เก็บโค้ดเพียงแอพเดียว แต่เรายังสามารถนำไป Deploy ได้หลายที่เชียวหละ ไม่ว่าจะเป็นการ deploy ลง Product, Staging หรือแม้กระทั่งบนเครื่องของนักพัฒนาเองก็ตาม
การ Deploy ต่างที่นั้นเราไม่จำเป็นต้อง deploy ทุก commits เหมือนกัน เราอาจ Deploy commits ล่าสุดไปบน Staging และเมื่อไหร่ที่ผ่านการทดสอบอย่างพอเพียงแล้วเราถึงนำ commit ดังกล่าวเข้าสู่ Production ต่อไป
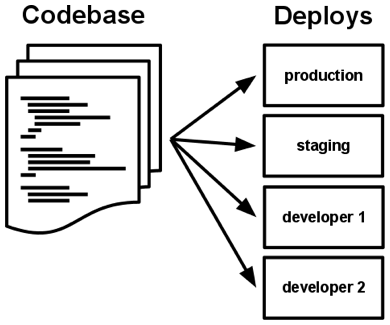
ข้อดีของบัญญัตินี้คือ นักพัฒนาที่เข้ามาสู่โปรเจคจะพร้อมเริ่มทำงานทันทีเพียงแค่เข้าถึง Codebase เดียว แถม Codebase เดียวยังเปรี้ยวได้ทุกงาน ใช้ที่ไหนก็ได้ โตแล้วแม่ไม่ว่า!
บัญญัติข้อที่ 2: Dependencies
ยาวไปไม่อ่าน: ระบุ package และเลขเวอร์ชันที่ใช้งานในแอพอย่างชัดเจนใน Codebase
เมื่อเรามี Repository ไว้จัดเก็บโค้ดของเราแล้ว เพื่อให้ Codebase ของเราสมบูรณ์พร้อม เราก็ควรบอกด้วยว่าโค้ดของเราต้องการใช้งาน Library หรือ Package อื่นใดเพิ่มเติมหรือไม่
ในสถานการณ์ที่เราต้องการ nodemon , ซึ่งเป็น package ตัวหนึ่งของ Node.js ที่ใช้ตรวจสอบการเปลี่ยนแปลงไฟล์บนเครื่องก่อนทำการ Reload ใหม่, เราอาจจะใช้วิธีบอกต่อในทีมว่า ก่อนจะ run โปรเจค พวกคุณมึงโปรดติดตั้ง nodemon ก่อนนะ หากใครไม่ทำตามความอิ๊บอ๋ายก็จะมาเยือน เพราะโปรเจคมัน run ไม่ขึ้นหนะซิ!
วิธีการแบบพรายกระซิบข้างต้นเกิดความวุ่นวายแน่นอน ไหนจะเวอร์ชันของ lib ไม่ตรงกันเพราะต่างคนต่างก็ลงเองตามมีตามเกิด สำคัญสุดคือหัวหน้าทีมต้องคอยเป็นโทรโข่งเคลื่อนที่ ทำเอกสารอธิบายการติดตั้งยืดยาวซึ่งมันเสียเวลาทำมาหากินมาก
ไหนๆเราก็คุมโค้ดด้วย Codebase แล้ว ทำไมเราไม่ใช้ Codebase ของเราให้เป็นประโยชน์?
ใส่ Dependency ของเราลงไปใน Codebase เลยซิ commit ไฟล์ที่ใช้จัดการ Dependency ของเราเช่น package.json เข้าไปใน Version Control ด้วยครับ ใครเพิ่ม Dependency อะไรไปจะได้รู้ได้เห็นกันทั้งทีม
1{2 "main": "index.js",3 "dependencies": {4 ...5 },6 "devDependencies": {7 "nodemon": "^1.11.0"8 },9 "scripts": {10 "dev": "nodemon ./index.js"11 }12}
เพียงระบุ nodemon เข้าไปใน package.json ทุกอย่างก็แฮปปี้ แค่ออกคำสั่ง npm install ชีวิตก็ง่ายขึ้น ไม่ต้องให้ใครมาบอกว่าต้องติดตั้ง package อะไรก่อน run โปรแกรมบ้างอีกต่อไป ซื้อเลย!
แต่ช้าก่อน! การที่เราบอก npm ว่าเราต้องการ nodemon เวอร์ชัน ^1.11.0 ไอ้เครื่องหมาย ^ แบบนี้หมายความว่า npm อาจไปติดตั้ง nodemon เวอร์ชัน 1.12.0 มาให้เราก็เป็นได้ นั่นเพราะเราไม่ได้ระบุเลขเวอร์ชันที่ตรงตัวลงไปเลย
ใน Package Manager เช่น Rubygems เราแก้ปัญหานี้ด้วยการสร้าง Gemfile.lock ขึ้นมา ไฟล์ดังกล่าวจะมีการระบุเลขเวอร์ชันที่แท้จริงเอาไว้ ว่าแท้จริงแล้วแอพของเราใช้งาน package เวอร์ชันอะไรกันแน่
กรณีของ Yarn เราก็มี yarn.lock เช่นกันที่จะเก็บเวอร์ชันที่แท้จริงของ package ที่เราใช้งานอยู่ อย่าลืม commit ไฟล์ lock พวกนี้เข้าไปใน version control ด้วยละ!
1// yarn.lock2nodemon@^1.11.0:3 version "1.11.0"4 resolved "https://registry.yarnpkg.com/nodemon/-/nodemon-1.11.0.tgz#226c562bd2a7b13d3d7518b49ad4828a3623d06c"5 dependencies:6 chokidar "^1.4.3"7 debug "^2.2.0"8 es6-promise "^3.0.2"9 ignore-by-default "^1.0.0"10 lodash.defaults "^3.1.2"11 minimatch "^3.0.0"12 ps-tree "^1.0.1"13 touch "1.0.0"14 undefsafe "0.0.3"15 update-notifier "0.5.0"
ข้อดีของบัญญัตินี้คือ นักพัฒนาอย่างเราจะปวดตับน้อยลง no สน no แคร์ ว่าเราจะต้องติดตั้งแพคเกจอะไรบ้าง เลขเวอร์ชันของแพคเกจเป็นอะไร แค่สั่ง npm install ทุกอย่างจบ จบนะ!
บัญญัติข้อที่ 3: Config
ยาวไปไม่อ่าน: เก็บ config ต่างๆใน Environment Variables
หนึ่ง Codebase ของเราสามารถ Deploy ได้หลายที่ ในแต่ละที่นั้นก็จะมีสภาพแวดล้อมที่ไม่เหมือนกัน เช่นฐานข้อมูลบน Staging และ Production ก็จะเป็นคนละตัวกัน เมื่อเป็นเช่นนี้เราควรจัดการ config ของเราให้สามารถเปลี่ยนแปลงได้ตามแต่สถานที่ที่มันสิงอยู่
หลายคนอาจเคยยัดการตั้งค่าต่างๆลงไปในโค้ดโดยตรงแบบนี้...
1// ติดต่อฐานข้อมูลด้วย username คือ babelcoder2// และรหัสผ่านคือ moab-dead--dead---dead3db.connect('babelcoder', 'moab-dead--dead---dead', error => {4 ...5})
แน่นอนว่าวิธีข้างต้นเราจะไม่สามารถโยกโค้ดของเราไปใช้งานที่อื่นได้ เพราะฐานข้อมูลที่อื่นอาจไม่มี username/password เช่นที่ว่า อีกประการหนึ่งคือข้อมูลที่สำคัญขนาดนี้ คุณจะกล้า commit เข้าไปใน Repository เชียวหรือ?
วิธีที่ดีกว่าคือการตั้งค่า config เหล่านี้ไว้ในตัวแปร ENV เมื่อเราย้ายไปแพลตฟอร์มอื่นก็แค่ไปตั้งค่า config เหล่านี้ให้ถูกต้องบนแพลตฟอร์มนั้นๆ
1// อ่านค่า USERNAME และ PASSWORD จากตัวแปร ENV ของแพลตฟอร์มนั้นๆแทน2db.connect(process.env.USERNAME, process.env.PASSWORD, error => {3 ...4})
ข้อดีของบัญญัตินี้คือ เราสามารถย้ายโค้ดของเราไปทำงานต่างแพลตฟอร์มได้โดยไม่ต้องกังวลว่าจะเปลี่ยนแปลง config ในโค้ดเรายังไง สิ่งที่เราทำคือการแก้ ENV ตามแต่แพลตฟอร์มนั้นโดยไม่ต้องแตะต้องโค้ดเดิม
บัญญัติข้อที่ 4: Backing services
ยาวไปไม่อ่าน: Backing services ต้องพร้อมสำหรับการถูกแทนที่ โดยที่โค้ดของเรายังเหมือนเดิม
Backing Services ก็คือบริการที่แอพเราไปเรียกใช้ เช่น ฐานข้อมูล เป็นต้น
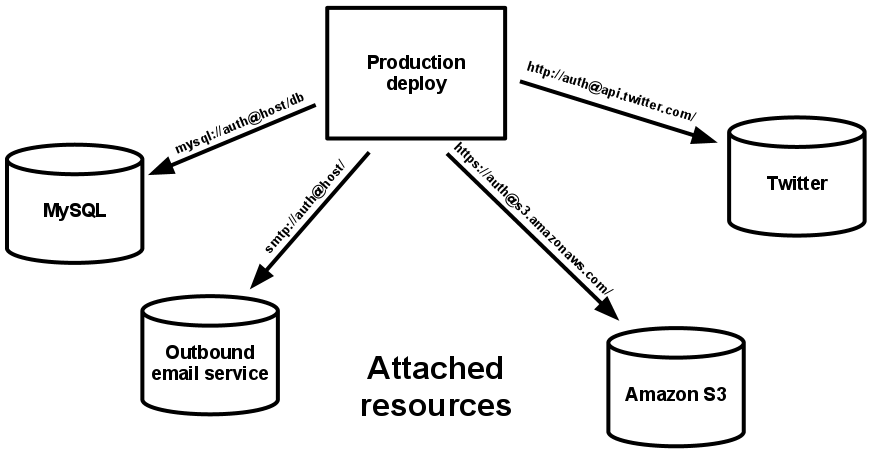
การออกแบบแอพพลิเคชันของเราต้องถือว่า Backing Services เป็นทรัพยากรตัวหนึ่งที่พร้อมจะถูกแทนที่ได้เสมอ โดยที่การแทนที่นั้นต้องไม่กระทบกับโค้ดของเรา ตัวอย่างเช่นการติดต่อกับฐานข้อมูลไม่ควรเป็นเราอาจไม่รับ USERNAME, PASSWORD เท่านั้น เพราะฐานข้อมูลที่เราใช้อาจอยู่บนเครื่องอื่นก็เป็นได้
1// แค่ USERNAME, PASSWORD ไม่เพียงพอ เพราะฐานข้อมูลอาจอยู่ที่ network อื่น2db.connect(process.env.USERNAME, process.env.PASSWORD, error => {3 ...4})
เมื่อเป็นเช่นนี้ เราอาจตั้งค่าให้การติดต่อกับฐานข้อมูลเราทำผ่าน connection string แทน เช่น mysql://lkasjdl@babelcoder/db
1// แค่ USERNAME, PASSWORD ไม่เพียงพอ เพราะฐานข้อมูลอาจอยู่ที่ network อื่น2db.connect(process.env.DATABASE_URL, error => {3 ...4})
บัญญัติข้อที่ 5: Build, release, run
ยาวไปไม่อ่าน: แบ่งการ Deploy ออกเป็น Build, Release และ Run Stages อย่างชัดเจน
และแล้วเมื่อแอพของเราพัฒนาไปถึงระดับหนึ่ง ตอนนี้ก็พร้อมสำหรับการ deploy แล้ว...
บัญญติข้อนี้แนะนำให้เราแบ่งขั้นตอนการ Deploy ออกเป็น 3 Stages ด้วยกัน
- Build Stage: ขั้นตอนนี้จะเป็นการสร้างโปรแกรมที่พร้อมทำงาน อาศัยโค้ดจาก commit ที่เราจะ deploy เป็นตัวตั้งและใช้ package ต่างๆที่ระบุไว้ว่าจะใช้งานเป็นส่วนผสม ปรุงคลุกเคล้าด้วยกันออกมาเป็น Executable Bundle ที่พร้อมจะนำไปใช้งานต่อ
- Release Stage: เพราะสภาพแวดล้อมของแพลตฟอร์มแตกต่างกัน ขั้นตอนของการ Release จึงต้องอ่านค่า config ต่างๆที่ได้ตั้งไว้เป็นตัวแปรของ ENV เพื่อนำไปใช้คู่กับผลลัพธ์จาก Build Stage โดยทั่วไปการ Release ซอฟต์แวร์เราจะมีตัวเลขเวอร์ชันที่ไม่ซ้ำกันกำกับเสมอ เพื่อให้ง่ายต่อการระบุว่าต้องการใช้ Release ไหนในการทำงาน หากมีปัญหาเกิดขึ้นเราก็ยังย้อนกลับไปยัง Release ก่อนหน้าได้อีกด้วย
- Run Stage: ช่วงของ Runtime เป็นการ run แอพที่ผ่านการตั้งค่าจาก Release Stage เป็นที่เรียบร้อยแล้วมาใช้ทำงานตามแต่สภาพแวดล้อมนั้นๆ
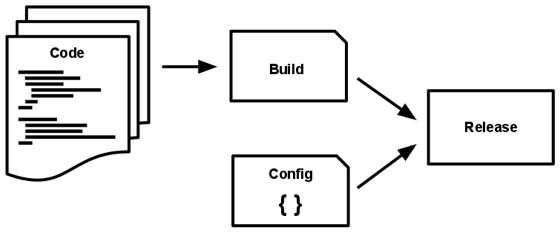
การแบ่งแยกขั้นตอนอย่างชัดเจนทำให้นักพัฒนาอย่างไรปวดตับน้อยลง หลักการของการออกแบบตามขั้นตอนนี้ เราจะผลักภาระงานที่ซับซ้อนให้กับ Build Stage เพราะในจังหวะของการ Build แน่นอนว่าโปรแกรมของเรายังไม่ได้ทำงานจริงๆ หากเกิดข้อผิดพลาด โปรแกรมเมอร์อย่างเราก็จะรู้และเห็น พร้อมทั้งสามารถปรับแก้ได้ทันท่วงที่ ส่วน Runtime (Run Stage) ต้องเป็นขั้นตอนที่ไวและซับซ้อนน้อยสุดแทน
ตัวอย่างของการออกแบบตามบัญญัตินี้ เช่น การจัดการ assets ต่างๆ ในกรณีที่เว็บเรามีไฟล์ CSS หลายไฟล์ เราอาจจะอยากรวมไฟล์ดังกล่าวให้เป็นก้อนเดียวพร้อมทั้งลดขนาดไฟล์ไปด้วย ขั้นตอนเหล่านี้ถือว่าเป็นงานซับซ้อน เราจึงต้องจัดการใน Build Stage ไม่ใช่ใน Run Stage เป็นต้น
บัญญัติข้อที่ 6: Processes
ยาวไปไม่อ่าน: อย่าจัดเก็บข้อมูลบนโปรเซส แต่จงใช้บริการ Backing Services แทน
เมื่อเราสั่ง run โค้ดของเรา Process ก็จะเกิดขึ้น ในสถานการณ์ที่เราต้องการให้เว็บของเรารองรับปริมาณผู้ใช้งานมหาศาล เราอาจสั่ง run หลาย Process ขึ้นมาทำงาน พร้อมทั้งใช้ Load Balancer เป็นตัวจัดการโหลดของการใช้งาน
เพื่อไม่ให้การทำงานของเราต้องประมวลผลใหม่ทุกครั้ง เราจึงมีการ Cache ข้อมูลเก็บไว้ภายใต้หน่วยความจำของ Process นั้นๆ คุณคิดว่าวิธีการนี้ดีพอหรือไม่?
เมื่อผู้ใช้งานระบบเข้ามา Load Balancer ส่งต่อการทำงานไปให้ Process A ทำงาน เพื่อลดภาระที่ต้องประมวลผลครั้งถัดไป Process A จึงแคชผลลัพธ์เก็บไว้ในหน่วยความจำของตน ช่างโชคร้ายที่ครั้งถัดไปเมื่อผู้ใช้เข้ามาใช้งานในระบบ Load Balancer ตัวดีดันส่งการทำงานต่อไปให้ Process B แน่นอนว่า Process B ไม่ได้มีแคชของการทำงานเก็บเอาไว้ เมื่อเป็นเช่นนี้การประมวลผลใหม่จึงเกิดขึ้น สถานการณ์แบบนี้การทำแคชบนแต่ละ Process จะมีความหมายอะไร?
บัญญัติข้อนี้กล่าวไว้ว่าแอพพลิเคชันเราแม้จะมีหนึ่งหรือหลายโปรเซสก็ตาม แต่สิ่งที่สำคัญคือมันจะต้องเป็น Stateless Process นั่นคือห้ามมีการจำสถานะบนตัวมัน หากต้องการจำค่าอะไรซักอย่าง จงใช้บริการของ Backing Services แทน
สถานการณ์ข้างต้นเราจึงกล่าวได้ว่า หากเราต้องการเก็บแคช การใช้บริการ Backing Service อย่าง Memcached หรือ Redis จึงดีกว่า แม้ว่า Load Balancer จะส่งต่อ Request มาที่โปรเซสใด โปรเซสนั้นๆก็แค่ดึงและจัดเก็บข้อมูลจาก Redis แค่นี้เอง
บัญญัติข้อที่ 7: Port binding
ยาวไปไม่อ่าน: แอพพลิเคชันของเราจะเป็นบริการที่ต้องให้บริการผ่าน Port เท่านั้น
เพื่อให้แอพของเราสามารถโยกย้ายข้ามแพลตฟอร์มได้โดยง่าย แอพพลิเคชันในอุดมคติจึงต้องสมบูรณ์พร้อมในตนเอง นั่นคือตัวแอพพลิเคชันจะไม่ผูกติดกับ webserver ขนาดที่ว่าต้องมีการติดตั้ง Webserver นั้นๆก่อนเพื่อนำแอพพลิเคชันของเราไป deploy ใส่อีกที
เมื่อแอพพลิเคชันของเรามีไว้เพื่อให้บริการ เราจำเป็นต้องให้ผู้ใช้เข้าถึงได้โดยง่ายผ่าน PORT ของ HTTP
แอพพลิเคชันใน 12 factors จะทำตนเป็น Service เพื่อให้บริการผ่าน PORT ที่ระบุ เมื่อเป็นเช่นนี้จึงกล่าวได้ว่าแอพพลิเคชันของเราก็สามารถกลายเป็น Backing Service สำหรับแอพพลิเคชันอื่นที่ต้องการใช้บริการได้เช่นเดียวกัน
บัญญัติข้อที่ 8: Concurrency
ยาวไปไม่อ่าน: ขยายระบบด้วยการใช้ Process Model
ด้วยบัญญัติข้อนี้เราจะไม่ run โปรเซสของเราขึ้นมาโดยตรงด้วยการออกคำสั่งแบบเรียบง่าย เช่น
1$ ./memcached -vv
แต่เราจะใช้ Process Manager เช่น Upstart ใน Ubuntu เป็นตัวจัดการโปรเซสแทน ทั้งนี้เราจะมีการแบ่งโปรเซสออกเป็นชนิดต่างๆ เช่น web และ worker เป็นต้น โดย Process Type ชนิด web จะใช้จัดการ Request/Response ของแอพพลิเคชัน ในขณะที่ worker อาจเป็นงานประเภทที่ใช้เวลานาน เช่นการอัพโหลดไฟล์ไปยัง Amazon S3
เมื่อ process type ตัวไหนมีแนวโน้มที่เราต้องการใช้มากขึ้น เราก็แค่เพิ่มโปรเซสสำหรับชนิดนั้นเข้าไปเพิ่มเติมได้ เช่นเรามีงานที่ต้องประมวลผลจำนวนมาก เราจึงเพิ่ม worker ของเราเข้าไปเป็น 4 ตัวดังนี้
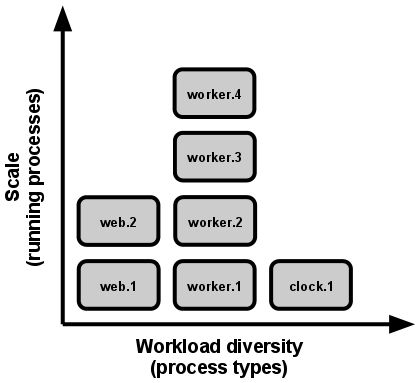
บัญญติข้อนี้จึงเป็นบัญญัติที่ช่วยให้เราสามารถขยายขนาดของระบบได้ง่ายขึ้นนั่นเอง
บัญญัติข้อที่ 9: Disposability
ยาวไปไม่อ่าน: แอพพลิเคชันเรา Startup Time ต้องไว และมีการจัดการข้อมูลให้เรียบร้อยเมื่อมีการ Shutdown
เมื่อแอพพลิเคชันของเรามีไว้เพื่อให้บริการงานใดงานหนึ่ง แอพพิลเคชันของเราจึงต้องมีความเสถียรและทนมือทนตีนมากหน่อยครับ ชนิดที่ว่าล่มทุกวันแบบนี้ก็ไม่ไหวนะ...
ธรรมกายยังมีจานบินฉันใด เว็บเราก็บินได้ฉันนั้น เราจึงต้องออกแบบแอพพลิเคชันให้รอบรับเหตุการณ์ที่คาดไม่ถึงไว้ด้วย
สถานการณ์ที่เว็บเราล่ม เราต้องมั่นใจว่าแอพพลิเคชันของเราจะจัดการข้อมูลได้อย่างถูกต้อง สำหรับเว็บแอพพลิเคชันเราแค่ไม่รับ Request ใหม่ที่ติดต่อเข้ามาในช่วงเว็บเราล่ม แต่สำหรับ Worker Process นั้นเราต้องมั่นใจว่าภายหลังการล่มครั้งนี้ งานที่กำลังทำอยู่ปัจจุบันต้องได้รับการกลับมาทำใหม่อีกครั้ง
เมื่อแอพพลิเคชันพร้อมที่จะเริ่มทำงานใหม่อีกครั้ง ช่วงเวลาการเริ่มทำงานต้องสั้น นั่นคือ Startup Time ต้องเร็ว ลองจินตนาการถึงสถานการณ์ที่เราต้อง Deploy โค้ดใหม่ไปยัง Production ครับ แน่นอนว่าเราต้องหยุดการทำงานปัจจุบันก่อน จากนั้นจึงเริ่มการทำงานของโค้ดหยุดใหม่ หากเวลาที่ใช้ในการเริ่มทำงานมันช้า เว็บเราก็เข้าไม่ได้เสียที
เพื่อป้องกันไม่ให้ผู้ใช้งานระบบเห็นรอยต่อของการ Deploy เราสามารถใช้หลักการของ Zero Downtime Deployment เข้าช่วยได้เช่นกัน
บัญญัติข้อที่ 10: Dev/prod parity
ยาวไปไม่อ่าน: ทำสภาพแวดล้อมของ Development, Staging และ Production ให้เหมือนกันมากที่สุด
หัวใจสำคัญของบัญญัติข้อนี้คือการทำให้ Development และ Production แตกต่างกันน้อยที่สุด
Time Gap
สถานการณ์ปัจจุบันหลายที่นิยมเขียนโค้ดเพื่อสร้างฟีเจอร์หลายฟีเจอร์ก่อนถึงค่อย Deploy แน่นอนว่ามันอาจกินเวลาแรมสัปดหา์หรือแรมเดือน หลังเวลาผ่านไปเป็นเดือนเราพึ่งจะได้ Deploy ขึ้น Staging หรือ Production นั่นหมายความว่าเราพึ่งจะได้เห็นผลลัพธ์ที่แท้จริงบนสภาพแวดล้อมของการใช้งานจริงหลังทุ่มเทแรงกายไปเป็นเดือน หากข้อผิดพลาดเกิดขึ้นก็จะเป็นการยากที่จะทราบว่าข้อผิดพลาดนี้มาจากฟีเจอร์ไหน
บัญญัติข้อนี้ต้องการให้เราทำทีละน้อยแล้ว Deploy ทันที เพื่อให้ Development กับ Staging/Production แตกต่างกันน้อยที่สุดนั่นเอง
Personnel Gap
บริษัทหลายแห่งมักแยก Developers ออกจาก Deployment Engineers อย่างชัดเจน แต่สำหรับบัญญัติข้อนี้ต้องการให้ผู้เขียนโค้ดเป็นคนๆเดียวกับผู้ที่ทำการ Deploy
Tools Gap
การใช้งานซอฟต์แวร์ให้ตรงกับที่ Production ใช้เป็นสิ่งสำคัญ
เพื่อนๆหลายคนอาจใช้ SQlite เป็นฐานข้อมูลบนเครื่องตนเองใน Development แต่เลือกใช้ MySQL เป็นฐานข้อมูลบน Production สถานการณ์แบบนี้เป็นสิ่งที่บัญญัติข้อนี้ไม่แฮปปี้
ซอฟต์แวร์ที่ต่างกันอาจมีการจัดการที่แตกต่างกัน บนเครื่องของเราอาจใช้คำสั่ง SQL นี้บน SQlite แล้วไม่มีปัญหา แต่จะรู้ได้ยังไงว่าเมื่อนำไปใช้กับ MySQL บน Production แล้วจะไม่มีปัญหาเช่นกัน? เมื่อเป็นเช่นนี้เราจึงควรใช้ซอฟต์แวร์ตัวเดียวและเลขเวอร์ชันเดียวกันกับบน Production เสมอ
เพื่อกำจัดความต่างของสภาพแวดล้อมในการทำงาน เทคโนโลยี Container อย่าง Docker ก็ถือเป็นอีกคำตอบหนึ่งในการพัฒนาแอพพลิเคชันของเราเช่นกัน
บัญญัติข้อที่ 11: Logs
ยาวไปไม่อ่าน: ทำ Logs ให้เป็น Event Streams
บัญญัติข้อนี้กล่าวไว้ว่า เมื่อเราใช้งานแอพพลิเคชันบน Development ให้ปล่อย Logs ออกมาทาง stdout (Standard Output Stream) เพื่อให้แสดงผลออกทางหน้าจอ (Terminal) ได้ เราๆท่านๆจะได้เห็นได้ทันทีโดยไม่ต้องไปเปิด logfile
กรณีของ Staging/Production แอพพลิเคชันของเราจะไม่ใช้ผู้จัดการ Logs โดยตรง แต่โปรเซสต่างๆจะทำการส่งออก Logs ออกในรูปแบบของ Stream จากนั้นจะมีซอฟต์แวร์อื่นเข้ามาจัดการเพื่อรวบรวม Logs เหล่านั้นแล้วส่งให้กับซอฟต์แวร์ที่ต้องการใช้งาน Logs เหล่านั้นอีกที
ข้อดีของบัญญัตินี้คือ เราจะสามารถตรวจดู Logs ตามเหตุการณืที่เราสนใจได้ภายหลังและสามารถนำข้อมูลของ Logs ดังกล่าวไปประมวลผลด้วยซอฟต์แวร์อื่นได้อีกทีนั่นเอง
บัญญัติข้อที่ 12: Admin processes
ยาวไปไม่อ่าน: เตรียมคำสั่งสำหรับงานแอดมินเพื่อสร้างโปรเซสที่ใช้ Release เดียวกับแอพพลิเคชันเรา
ภาพหลังการ Deploy แอพพลิเคชัน อาจมีงานอื่นทางด้านแอดมินที่เราต้องทำต่อ เช่น การทำ Database Migration หรือการเข้าสู่ REPL shell เพื่อออกคำสั่งโดยตรงไปยังแอพพลิเคชันของเรา
บัญญัติข้อนี้ต้องการให้เรามีคำสั่งสำหรับการทำงานด้าน Admin/Management โดยคำสั่งนี้จะทำการสร้างโปรเซสของการทำงานขึ้นมาใหม่ ไม่เกี่ยวข้องกับโปรเซสของแอพพลิเคชันเรา ทั้งนี้โปรเซสดังกล่าวต้องถูกทำลายเสียหลังการใช้งานเสร็จสิ้น นอกจากนี้โปรเซสที่เกิดขึ้นต้องใช้โค้ดชุดเดียวกันกับที่ใช้ทำงานแอพพลิเคชันเรา นั่นคือต้องเป็น Release เดียวกัน มีการตั้งค่า config เหมือนกันนั่นเอง ตัวอย่างการใช้งานเช่น
- คำสั่งทำ Database Migration ในแอพพลิเคชันของ Ruby on Rails คือ
rake db:migrate - คำสั่งเริ่มการทำงานของ REPL shell ในแอพพลิเคชันของ Ruby on Rails คือ
rails console
สรุป
หลังจากตรากตรำอ่านบทความอันแสนยาวนี้จบแล้ว เพื่อนๆคงจะเห็นข้อดีของการทำตามบัญญัติทั้ง 12 ประการของ Twelve Factor App กันแล้ว หากเพื่อนๆคนใดอยากเล่นของ ลองใช้งานแพลตฟอร์ม Heroku แบบฟรีดูซิ แล้วจะรู้ว่า 12 factor เขาใช้กันจริงๆยังไง
เอกสารอ้างอิง
Adam Wiggins (2012). The Twelve-Factor App. Retrieved April, 16, 2017, from https://12factor.net/
สารบัญ
- รู้จัก The Twelve-Factor App
- บัญญัติข้อที่ 1: Codebase
- บัญญัติข้อที่ 2: Dependencies
- บัญญัติข้อที่ 3: Config
- บัญญัติข้อที่ 4: Backing services
- บัญญัติข้อที่ 5: Build, release, run
- บัญญัติข้อที่ 6: Processes
- บัญญัติข้อที่ 7: Port binding
- บัญญัติข้อที่ 8: Concurrency
- บัญญัติข้อที่ 9: Disposability
- บัญญัติข้อที่ 10: Dev/prod parity
- บัญญัติข้อที่ 11: Logs
- บัญญัติข้อที่ 12: Admin processes
- สรุป
- เอกสารอ้างอิง


